Last modified: Jan 31 2026 at 10:09 PM • 5 mins read
Why is Deep Learning Taking Off?
Table of contents
- Introduction
- The Key Question: Why Now?
- Neural Network Performance at Different Scales
- Two Key Observations
- Technical Details: The Small Data Regime
- Three Forces Driving Deep Learning
- Algorithmic Breakthroughs
- The Iteration Cycle
- The Positive Feedback Loop
- Why Deep Learning Will Keep Getting Better
- Summary
Introduction
If the basic technical ideas behind deep learning have been around for decades, why are they only taking off now? This lesson explores the main drivers behind the rise of deep learning and will help you spot opportunities to apply these techniques in your organization.
The Key Question: Why Now?
Over the last few years, people often ask: “Why is deep learning suddenly working so well?”
Here’s the explanation through a simple diagram:
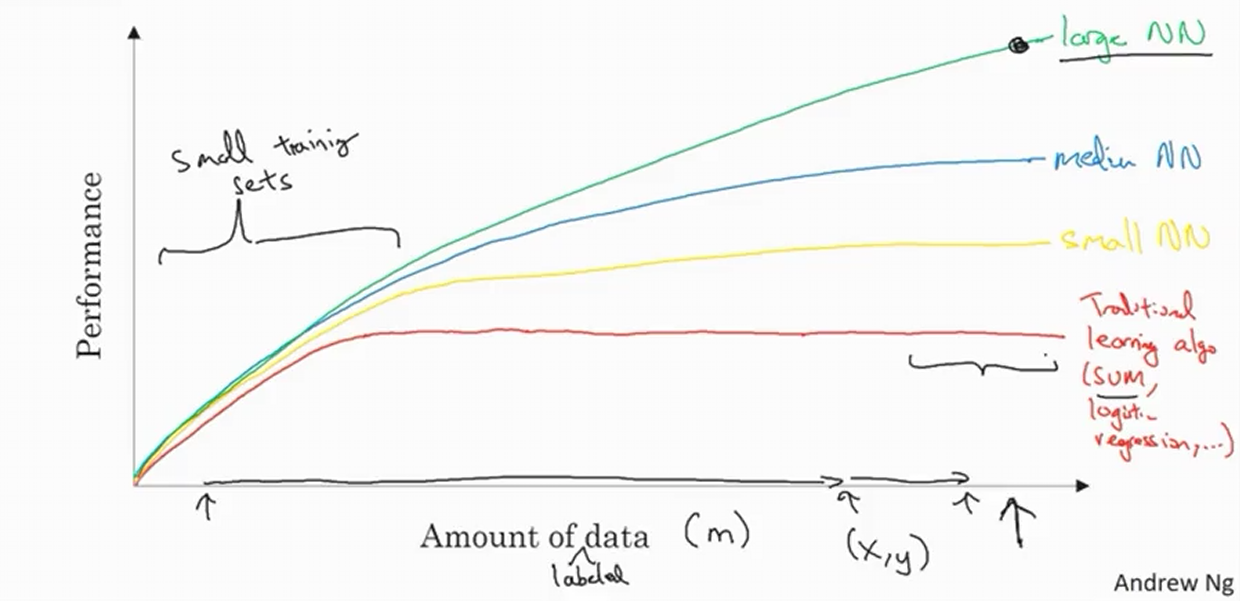
Understanding the Graph
Axes:
- Horizontal (X-axis): Amount of data available for a task
- Vertical (Y-axis): Performance of learning algorithms
- Examples: Accuracy of spam classifiers, ad click predictors, or self-driving car object detection
Traditional Machine Learning Performance
Traditional algorithms (like Support Vector Machines or Logistic Regression) show a characteristic pattern:
- Performance improves as you add more data
- After a certain point, performance plateaus
- They don’t know what to do with huge amounts of data
The Data Revolution
What changed over the last 10-20 years:
We went from having relatively small amounts of data to having massive datasets, thanks to:
Digitization of Society:
- More time spent on computers, websites, and mobile apps
- Digital activities create data continuously
Ubiquitous Sensors:
- Inexpensive cameras in cell phones
- Accelerometers in devices
- Internet of Things (IoT) sensors everywhere
Result: We accumulated far more data than traditional algorithms could effectively use.
Neural Network Performance at Different Scales
Neural networks behave differently based on their size:
Small Neural Network
- Performance curve similar to traditional ML
- Eventually plateaus with more data
Medium Neural Network
- Better performance than small networks
- Can utilize more data effectively
Large Neural Network
- Performance keeps improving with more data
- No clear plateau in the big data regime
Two Key Observations
To achieve very high performance, you need both:
- Large enough neural network to take advantage of huge amounts of data
- Sufficient data (large position on the X-axis)
Scale Drives Progress
“Scale” in deep learning means:
- Size of neural network:
- More hidden units
- More parameters
- More connections
- Scale of data:
- More training examples
- Larger datasets
Most reliable ways to improve performance:
- Train a bigger network
- Feed it more data
Limitation: This works until you run out of data or the network becomes too large/slow to train.
Technical Details: The Small Data Regime
Training Set Size Notation
- Lowercase $m$: Denotes the number of training examples
- Labeled data: Training examples with both input ($x$) and label ($y$)
Performance in Small Data Regime
When you have limited training data:
- Algorithm ordering is not well-defined
- Performance depends heavily on feature engineering skills
- A skilled practitioner with an SVM might outperform someone with a large neural network
- Success depends on:
- Hand-engineering features
- Algorithm-specific details
Performance in Big Data Regime
With very large training sets (large $m$):
- Large neural networks consistently dominate other approaches
- The advantages of deep learning become clear
- Feature engineering becomes less critical
Three Forces Driving Deep Learning
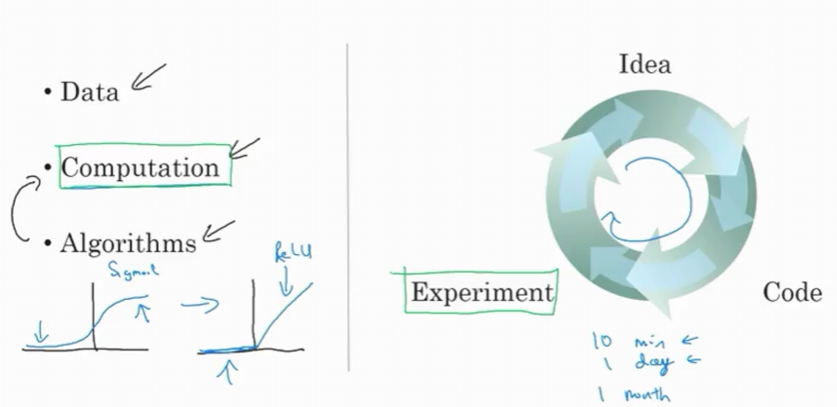
1. Data
Then:
- Small datasets
- Limited digital information
Now:
- Massive datasets from digital activities
- Continuous data generation from IoT devices
- Society producing more digital data every day
2. Computation
Evolution:
- Early days: Ability to train large neural networks on CPUs/GPUs
- Current: Specialized hardware (GPUs, TPUs)
- Impact: Can train much larger networks faster
Scale of computation enabled unprecedented progress in neural network training.
3. Algorithms
While scale drove early progress, algorithmic innovation has been crucial, especially in recent years.
Algorithmic Breakthroughs
Example: Sigmoid vs ReLU Activation Functions
Sigmoid Function Problem:
\[\sigma(z) = \frac{1}{1 + e^{-z}}\]Issues:
- Regions where gradient (slope) is nearly zero
- Learning becomes very slow
- Parameters change slowly when gradient ≈ 0
ReLU Function Solution:
\[\text{ReLU}(z) = \max(0, z) = \begin{cases} 0 & \text{if } z < 0 \\ z & \text{if } z \geq 0 \end{cases}\]Advantages:
- Gradient = 1 for all positive input values
- Gradient much less likely to shrink to zero
- Makes gradient descent work much faster
Impact: This simple change made computation dramatically faster, enabling larger networks and more experiments.
The Iteration Cycle
Fast computation matters because of the development cycle:
Idea → Implementation → Experiment → Results → Insights → New Idea
Speed Matters
Fast Training (10 minutes to 1 day):
- Try many ideas quickly
- Rapid iteration
- Higher productivity
- More discoveries
Slow Training (weeks to months):
- Long feedback cycles
- Fewer experiments
- Slower progress
- Limited exploration
Impact on productivity:
- 10-minute feedback: Try dozens of ideas per day
- 1-month feedback: Try only 12 ideas per year
This speed advantage benefits both:
- Practitioners: Building applications
- Researchers: Advancing the field
The Positive Feedback Loop
Many algorithmic innovations aim to make neural networks run faster, which:
- Enables training bigger networks
- Allows processing more data
- Speeds up the iteration cycle
- Leads to more discoveries
- Creates better algorithms
This creates a virtuous cycle of continuous improvement.
Why Deep Learning Will Keep Getting Better
All three forces continue to strengthen:
Data
- Society generating more digital data daily
- New sources constantly emerging
- No sign of slowing down
Computation
- Specialized hardware (GPUs, TPUs) improving rapidly
- Faster networking
- Cloud computing expanding
- Confident that computational capabilities will keep advancing
Algorithms
- Deep learning research community making continuous progress
- Constant innovation and breakthroughs
- Strong collaboration and knowledge sharing
Summary
Key Takeaways:
- Scale drives performance: Both network size and data quantity matter
- Three forces: Data, computation, and algorithms all improving
- Speed enables iteration: Fast training → more experiments → better results
- Positive outlook: All three forces continue to strengthen
For your organization:
- Look for opportunities with large datasets
- Invest in computational resources
- Stay current with algorithmic innovations
- Build fast iteration capabilities
The combination of these factors means deep learning will continue to improve for many years to come, creating ongoing opportunities for innovation and applications.