Last modified: Jan 31 2026 at 10:09 PM • 5 mins read
Dropout Regularization
Table of contents
- Introduction
- The Dropout Concept
- Implementing Inverted Dropout
- Understanding Inverted Dropout Scaling
- Training vs. Test Time
- Dropout Variations Across Layers
- Implementation Best Practices
- Comparison: Dropout vs. L2 Regularization
- Key Takeaways

Introduction
Dropout is a powerful regularization technique that randomly “drops out” (eliminates) neurons during training. Unlike L2 regularization which penalizes large weights, dropout creates an ensemble effect by training many different “thinned” versions of the network.
The Dropout Concept
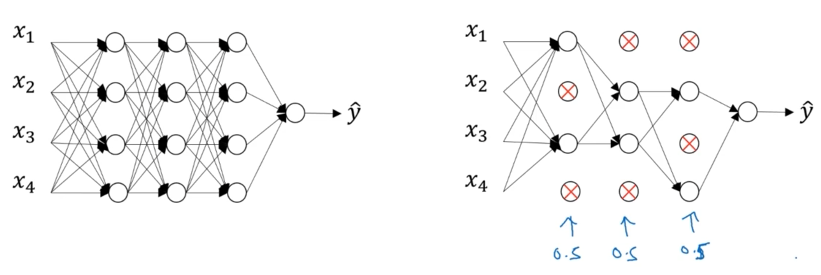
How Dropout Works
For each training iteration:
- Random Selection: For each layer, randomly eliminate neurons with probability $(1 - \text{keep_prob})$
- Network Reduction: Remove selected neurons and all their connections
- Train Reduced Network: Perform forward and backpropagation on this smaller network
- Repeat: For each training example, randomly drop different neurons
Visualization
| Stage | Description |
|---|---|
| Full Network | Complete neural network before dropout |
| Apply Dropout | Randomly eliminate 50% of neurons (if keep_prob = 0.5) |
| Reduced Network | Train on smaller “thinned” network |
| Next Iteration | Different random neurons dropped |
Key Insight: Each training example sees a different “architecture,” preventing neurons from relying too heavily on specific other neurons (co-adaptation).
Implementing Inverted Dropout
The Standard Implementation
Inverted dropout is the most common and recommended implementation. It handles scaling during training rather than at test time.
Step-by-Step Implementation for Layer 3
Step 1: Create Dropout Mask
# Generate random dropout mask
d3 = np.random.rand(a3.shape[0], a3.shape[1]) # Same shape as a3
d3 = (d3 < keep_prob) # Boolean mask: True = keep, False = drop
Step 2: Apply Mask to Activations
# Zero out dropped neurons
a3 = a3 * d3 # Element-wise multiplication
# Or equivalently: a3 *= d3
Step 3: Scale Up (Inverted Dropout)
# Scale activations to maintain expected value
a3 = a3 / keep_prob
# Or equivalently: a3 /= keep_prob
Complete Code Example
# Training with inverted dropout for layer 3
keep_prob = 0.8 # Keep 80% of neurons, drop 20%
# Forward propagation
z3 = np.dot(W3, a2) + b3
a3 = np.tanh(z3) # Or any activation function
# Apply dropout
d3 = np.random.rand(a3.shape[0], a3.shape[1]) < keep_prob
a3 *= d3 # Zero out dropped neurons
a3 /= keep_prob # Scale up remaining neurons
# Continue with next layer
z4 = np.dot(W4, a3) + b4
# ...
Understanding Inverted Dropout Scaling
Why Scale by keep_prob?
Consider a layer with 50 neurons and $\text{keep_prob} = 0.8$:
Without Scaling:
- On average, 20% of neurons (10 units) are zeroed out
- Expected value: $E[a^{[3]}] = 0.8 \times a^{[3]}_{\text{original}}$
- Next layer receives 20% less input than expected
- Problem: $z^{[4]} = W^{[4]}a^{[3]} + b^{[4]}$ is reduced by 20%
With Inverted Dropout Scaling:
\[a^{[3]} = \frac{a^{[3]} \odot d^{[3]}}{\text{keep_prob}}\]- Dividing by 0.8 compensates for the 20% reduction
- Expected value preserved: $E[a^{[3]}] = a^{[3]}_{\text{original}}$
- No scaling needed at test time
Mathematical Justification
\[E[a^{[3]}_{\text{scaled}}] = E\left[\frac{a^{[3]} \odot d^{[3]}}{\text{keep_prob}}\right] = \frac{\text{keep_prob} \cdot a^{[3]}}{\text{keep_prob}} = a^{[3]}\]Training vs. Test Time
During Training
# Apply dropout on every forward pass
for iteration in range(num_iterations):
# Different random dropout mask each iteration
d3 = np.random.rand(a3.shape[0], a3.shape[1]) < keep_prob
a3 *= d3
a3 /= keep_prob
# Backpropagation also uses the same mask
da3 *= d3
da3 /= keep_prob
Important: Use a different random dropout mask for:
- Each training example
- Each pass through the training set
- Each layer (with potentially different keep_prob values)
During Testing
# NO dropout at test time
z1 = np.dot(W1, a0) + b1
a1 = g1(z1)
z2 = np.dot(W2, a1) + b2
a2 = g2(z2)
z3 = np.dot(W3, a2) + b3
a3 = g3(z3)
# ... and so on
# Make prediction without randomness
y_pred = a_L
Critical: Never apply dropout during prediction/testing. You want deterministic outputs, not random ones.
Why No Dropout at Test Time?
| Approach | Pros | Cons |
|---|---|---|
| Dropout at test | Ensemble averaging | Computationally expensive, random outputs |
| No dropout (inverted) | Fast, deterministic | Requires proper training-time scaling ✓ |
Inverted dropout advantage: Because we scaled during training, test time requires no modifications—just use all neurons with their learned weights.
Dropout Variations Across Layers
Different layers can have different keep_prob values:
# Layer-specific dropout rates
keep_prob_1 = 1.0 # Input layer: no dropout
keep_prob_2 = 0.9 # First hidden: 10% dropout
keep_prob_3 = 0.5 # Second hidden: 50% dropout (prone to overfitting)
keep_prob_4 = 0.8 # Third hidden: 20% dropout
keep_prob_output = 1.0 # Output layer: no dropout
Rule of thumb: Apply stronger dropout (lower keep_prob) to layers with more parameters or those prone to overfitting.
Implementation Best Practices
Key Points
- Use inverted dropout: Industry standard, simplifies test time
- Different masks per iteration: Ensures true randomness
- No dropout at test time: Use full network for predictions
- Layer-specific rates: Adjust keep_prob based on layer size and overfitting risk
- No dropout for input/output: Usually keep these layers intact
Common Mistakes to Avoid
❌ Wrong: Same dropout mask for all training examples ❌ Wrong: Applying dropout at test time ❌ Wrong: Forgetting to scale by keep_prob (non-inverted dropout) ❌ Wrong: Using dropout when no overfitting exists
✅ Correct: Random mask per iteration + inverted scaling + no test-time dropout
Comparison: Dropout vs. L2 Regularization
| Aspect | Dropout | L2 Regularization |
|---|---|---|
| Mechanism | Randomly eliminate neurons | Penalize large weights |
| Implementation | Modify forward/backward pass | Add term to cost function |
| Computation | Slightly faster (fewer neurons) | Full network always used |
| Test Time | No modification needed (inverted) | No modification needed |
| Tuning Parameter | keep_prob per layer | Single $\lambda$ |
| Best For | Large networks, computer vision | Any network, interpretable |
Key Takeaways
- Ensemble Effect: Dropout trains many “thinned” networks, creating ensemble-like behavior
- Inverted Dropout: Scale during training ($a /= \text{keep_prob}$) to avoid test-time scaling
- Random Per Iteration: Use different dropout masks for each training example
- No Test-Time Dropout: Use full network with all neurons for predictions
- Expected Value Preservation: Inverted dropout maintains activation scale across train/test
- Layer-Specific Rates: Adjust keep_prob based on overfitting tendency per layer
- Industry Standard: Inverted dropout is the recommended implementation