Last modified: Jan 31 2026 at 10:09 PM • 9 mins read
Basic Recipe for Machine Learning
Table of contents
- Introduction
- The Basic Recipe: A Two-Step Process
- Step 1: Does Your Algorithm Have High Bias?
- Step 2: Does Your Algorithm Have High Variance?
- The Complete Workflow
- Key Insights
- Practical Example
- Summary: The Recipe
- Key Takeaways
Introduction
Now that you can diagnose bias and variance problems, you need a systematic approach to fix them. This lesson presents a basic recipe for machine learning that will help you methodically improve your algorithm’s performance.
Unlike the old days of trial-and-error, this recipe gives you a clear decision framework based on your diagnosis.
The Basic Recipe: A Two-Step Process
Overview
After training your initial model, follow this systematic workflow:
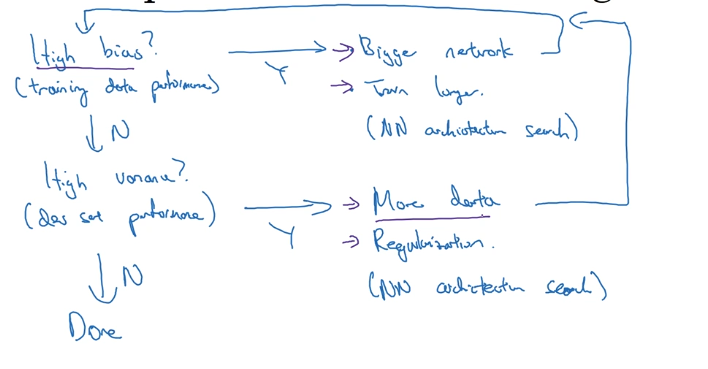
Let’s break down each step in detail.
Step 1: Does Your Algorithm Have High Bias?
How to Check
Question: Is your training set performance poor?
Metric to examine: Training error
Diagnosis:
- Training error much higher than Bayes error → High bias
- Training error close to Bayes error → Low bias (proceed to Step 2)
Solutions for High Bias (Underfitting)
If you have high bias, try these solutions in order of effectiveness:
1. Make Your Network Bigger ✅ (Almost Always Works)
Options:
- Add more hidden layers (go deeper)
- Add more hidden units per layer (go wider)
Why it works: Bigger networks have more representational capacity to fit complex patterns.
Example:
# Before: Small network
model = Sequential([
Dense(25, activation='relu'),
Dense(15, activation='relu'),
Dense(1, activation='sigmoid')
])
# After: Bigger network
model = Sequential([
Dense(128, activation='relu'), # More units
Dense(64, activation='relu'),
Dense(32, activation='relu'), # More layers
Dense(16, activation='relu'),
Dense(1, activation='sigmoid')
])
Cost: Computational time (but worth it!)
2. Train Longer ✅ (Usually Helps, Never Hurts)
Options:
- Increase number of epochs
- Continue training if loss is still decreasing
Why it works: Gives the optimizer more time to find better parameters.
Example:
# Before
model.fit(X_train, y_train, epochs=10)
# After
model.fit(X_train, y_train, epochs=100) # More epochs
Note: Only helpful if you haven’t converged yet. If training error has plateaued, training longer won’t help.
3. Try Advanced Optimization Algorithms ⚠️ (May Help)
Options:
- Adam optimizer (usually better than SGD)
- RMSprop
- Learning rate schedules
Why it works: Better optimizers can find better minima faster.
Example:
# Instead of basic SGD
from tensorflow.keras.optimizers import Adam
model.compile(
optimizer=Adam(learning_rate=0.001),
loss='binary_crossentropy'
)
4. Try Different Neural Network Architecture 🎲 (Maybe Works)
Options:
- CNN for images
- RNN/LSTM for sequences
- ResNet for very deep networks
- Attention mechanisms
Why it might work: Some architectures are better suited for specific problems.
Caveat: This is less systematic. You have to experiment to see what works.
When to Stop Fixing Bias
Goal: Keep iterating through these solutions until you can fit the training set well.
Success criteria: Training error is close to Bayes error (acceptable performance on training data).
Important assumption: The task should be humanly possible. If humans can do it well (low Bayes error), a big enough network should be able to fit the training data.
Exception: If the task is inherently difficult (e.g., extremely blurry images where even humans fail), then high training error might be unavoidable.
Step 2: Does Your Algorithm Have High Variance?
How to Check
Question: Does your model generalize poorly from training to dev set?
Metric to examine: Gap between dev error and training error
Diagnosis:
- Large gap (dev error ≫ training error) → High variance
- Small gap (dev error ≈ training error) → Low variance (you’re done!)
Solutions for High Variance (Overfitting)
If you have high variance, try these solutions:
1. Get More Data ✅ (Best Solution, If Possible)
Why it works: More data helps the model learn true patterns instead of memorizing noise.
Example scale-up:
Before: 10,000 examples
After: 100,000 examples (10x more)
Benefit: Almost always reduces variance without hurting bias.
Limitation: Sometimes you can’t get more data (expensive, time-consuming, or impossible).
Alternatives when you can’t get real data:
- Data augmentation (for images: rotation, flipping, zooming)
- Synthetic data generation
- Transfer learning from larger datasets
2. Use Regularization ✅ (Very Effective)
Options:
- L2 regularization (weight decay)
- L1 regularization (sparse weights)
- Dropout (randomly drop neurons during training)
- Early stopping
Why it works: Prevents the model from fitting noise in training data.
Example:
from tensorflow.keras.regularizers import l2
model = Sequential([
Dense(128, activation='relu', kernel_regularizer=l2(0.01)),
Dropout(0.5),
Dense(64, activation='relu', kernel_regularizer=l2(0.01)),
Dropout(0.3),
Dense(1, activation='sigmoid')
])
We’ll cover regularization in detail in the next lesson.
3. Try Different Neural Network Architecture 🎲 (Maybe Works)
Options:
- Simpler architecture (fewer parameters)
- Architecture with built-in regularization (BatchNorm)
- Ensemble methods
Caveat: Less systematic. Requires experimentation.
Note: The right architecture can help with both bias AND variance, but it’s harder to predict which changes will work.
When to Stop Fixing Variance
Goal: Keep trying solutions until dev error is close to training error.
Success criteria: Small gap between training and dev error.
The Complete Workflow
Iterative Process
1. Train initial model
2. Evaluate training error → High bias?
Yes → Apply bias solutions → Go back to step 2
No → Continue to step 3
3. Evaluate dev error → High variance?
Yes → Apply variance solutions → Go back to step 2
No → You're done!
Decision Table
| Training Error | Dev Error | Problem | Solutions |
|---|---|---|---|
| High | High | High bias (primarily) | Bigger network, train longer |
| Low | High | High variance | More data, regularization |
| High | Very high | Both bias and variance | Fix bias first, then variance |
| Low | Low | None | ✅ Deploy! |
Key Insights
1. Targeted Solutions Based on Diagnosis
Critical point: The solutions for high bias vs high variance are completely different.
Examples of wasted effort:
❌ Don’t do this:
- High bias problem → Getting more data (won’t help much)
- High variance problem → Making network bigger without regularization (makes it worse)
✅ Do this:
- High bias → Focus on representational capacity (bigger network, better architecture)
- High variance → Focus on generalization (more data, regularization)
2. The End of the Bias-Variance Tradeoff
Traditional Machine Learning Era (Pre-Deep Learning)
The tradeoff: Most techniques would:
- Reduce bias but increase variance, OR
- Reduce variance but increase bias
Example with polynomial regression:
- Higher degree polynomial → Lower bias, higher variance
- Lower degree polynomial → Higher bias, lower variance
Result: You had to carefully balance the two.
Modern Deep Learning Era
The breakthrough: We now have tools that reduce bias OR variance independently!
Two key tools:
| Tool | Effect | Condition |
|---|---|---|
| Bigger network | ⬇️ Bias, ➡️ Variance (if regularized) | Must regularize properly |
| More data | ➡️ Bias, ⬇️ Variance | As much as you can get |
Visual comparison:
Traditional ML (Tradeoff):
Bias ↓ → Variance ↑
Bias ↑ ← Variance ↓
Modern Deep Learning (No Tradeoff):
Bias ↓ ← Bigger network (with regularization)
Variance ↓ ← More data
3. Why Deep Learning Has Been So Successful
Major advantage: You can tackle bias and variance problems independently.
The strategy:
- Keep making network bigger → Reduce bias
- Keep adding more data → Reduce variance
- Use regularization → Prevent variance from increasing
Result: You don’t have to compromise!
Historical context: This is one of the biggest reasons deep learning has revolutionized supervised learning. The old tradeoff constraints no longer apply (as strongly).
4. Training a Bigger Network (Almost) Never Hurts
Claim: A bigger network is almost always better, with proper regularization.
Why it works:
- More parameters → More capacity → Can fit more complex patterns
- Regularization prevents overfitting
- At worst, the network learns to ignore extra capacity
Main cost: Computational time (training takes longer)
But: With modern GPUs and cloud computing, this is increasingly manageable.
Caveat: There’s a slight bias-variance tradeoff with regularization:
- Adding regularization might slightly increase bias
- But if your network is big enough, this increase is negligible
Practical Example
Scenario: Cat Classification
Initial results:
- Training error: 15%
- Dev error: 30%
- Human performance: ~0%
Diagnosis: High bias (15% training error) + High variance (15% gap)
Step-by-step solution:
Iteration 1: Fix Bias First
Action: Make network bigger
# Old: 2 layers, 20 units each
# New: 5 layers, 100 units each
Results:
- Training error: 5% ✅ (improved!)
- Dev error: 20% ⚠️ (still high variance)
Iteration 2: Now Fix Variance
Action: Add regularization + more data
# Add L2 regularization and dropout
# Collect 50,000 more training images
Results:
- Training error: 6% ✅ (slightly higher, but acceptable)
- Dev error: 7% ✅ (much better generalization!)
Conclusion: Low bias + low variance → Deploy!
Summary: The Recipe
Quick Reference
When you have high bias:
- ✅ Try bigger network (almost always helps)
- ✅ Train longer (usually helps, never hurts)
- ⚠️ Try advanced optimization
- 🎲 Try different architecture
When you have high variance:
- ✅ Get more data (if possible)
- ✅ Add regularization (very effective)
- 🎲 Try different architecture
When you have both:
- Fix bias first (get training error down)
- Then fix variance (get dev error down)
- Iterate until both are low
The Modern Deep Learning Advantage
In the era of big data and big networks:
- Bigger networks reduce bias without increasing variance (with regularization)
- More data reduces variance without increasing bias
- You can systematically reduce both independently
- The old bias-variance tradeoff is much less restrictive
Key Takeaways
- Systematic approach: Diagnose first (bias vs variance), then apply targeted solutions
- High bias solutions: Bigger network, train longer, better architecture
- High variance solutions: More data, regularization, simpler architecture
- Targeted interventions: Don’t waste time on solutions that don’t address your specific problem
- Fix bias first: If you have both problems, tackle bias before variance
- Bigger networks work: With regularization, bigger is almost always better
- More data works: Almost always reduces variance without hurting bias
- No more tradeoff: Deep learning lets you reduce bias and variance independently
- Regularization is key: Enables bigger networks without overfitting (next lesson!)
- Iterate systematically: Train → Diagnose → Fix → Repeat
- Computational cost: Main downside of bigger networks is training time
- Human performance: Use as baseline for what’s achievable (Bayes error)
- Keep iterating: Go through the cycle until both bias and variance are acceptable
- Modern advantage: Big data + big networks + regularization = unprecedented performance
- Next step: Master regularization techniques to complete your toolkit